前言
因为给学生上课的课程需要,以及我之后的学习,今天我打算了解一下算力云平台。这里我们使用之前一个学长给我安利的 AutoDL。
初见算力云平台
初见 AutoDL
首先看看导航栏:

这里最重要的是算力市场,我们租用算力云就在这个里面。另外算法社区也有一些 AI 项目的仓库和镜像,这里我们先不用。接着,在主页也可以看到算力云的价格,可以看到都是以小时计费的,具体的价格可以参考下图(当然会员会更便宜)。
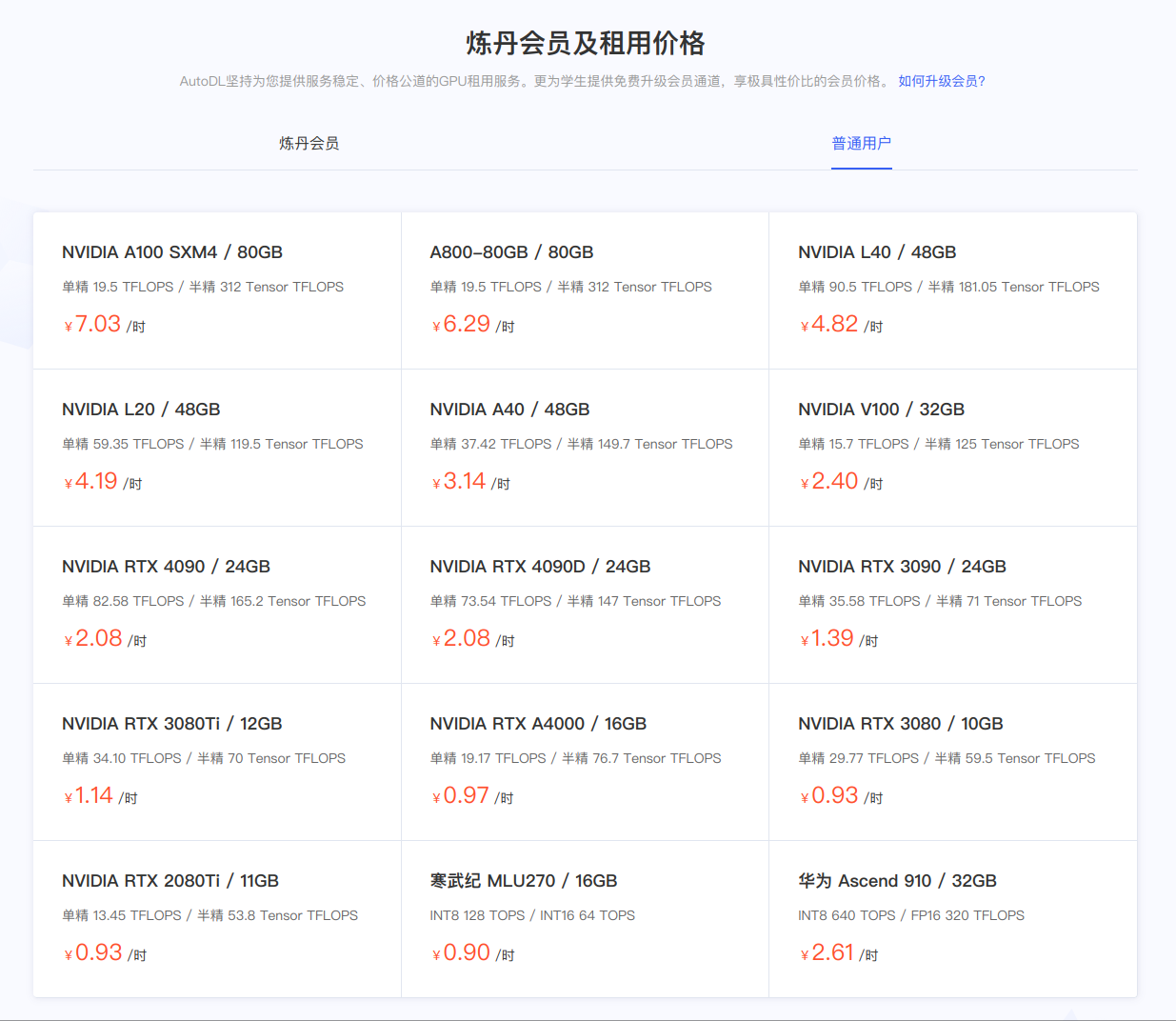
算力云租赁
接下来,我们进入算力市场,下面每一个地区都有对应的可用 GPU 型号。这里我选择了一个 GTX 1080 Ti,毕竟只是试用,就不租太贵了。
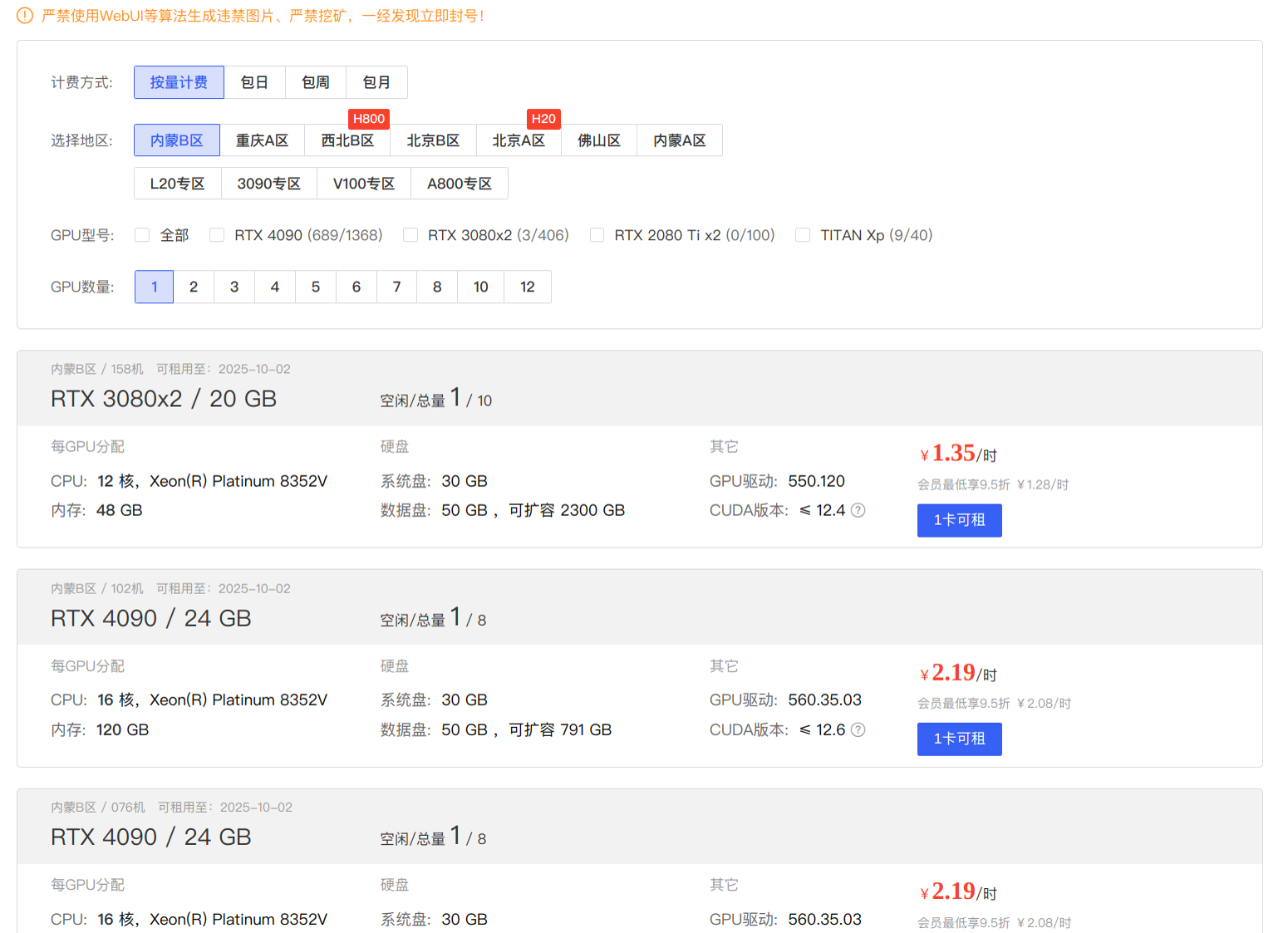
控制台
接着我们来到算力云控制台,可以看到我们是租用了一个 Docker 容器。我们可以自行上传数据创建数据卷,也可以使用现成的数据卷,里面有一些常用的数据集,比如 ImageNet,还有预训练 BERT 模型。当然我们也可以自制镜像创建容器,我这里是已经创建了一个容器,使用现成的 Miniconda 镜像。
使用容器实例
在控制台中,进入容器实例选项卡,可以看到我们租用的容器。可以看到,我们可以使用 JupyterLab 或 SSH 对容器进行操作,AutoDL 也提供了一个面板 AutoPanel 对容器进行管理。我们也可以开放自己的算力服务,具体操作可以看下面的 “快捷工具” 中的 “自定义服务” 链接。

使用 JupyterLab
点击上面的链接,就可以进入 JupyterLab 界面。我们可以看到挂载的数据卷和镜像里的 miniconda。我们也可以使用 JupyterLab 进行开发,不过我个人还是比较偏好用 jb,所以下面我们讲讲 SSH。
使用 SSH
我们在容器实例界面可以看到 SSH 指令和密码的复制链接,我们可以由此进入 SSH 终端。在 SSH 指令中我们可以看到用户名、主机名和端口,我们在 JetBrains 的 IDE 中使用上面的信息配置 SSH 远程解释器,具体可以看这里的 官方文档。
使用 JetBrains IDE 远程开发
这里我们以 PyCharm 为例,当然其他 IDE 也是异曲同工。
首先我们创建一个项目,然后配置解释器。这里我们根据之前拿到的 SSH 指令填入信息。
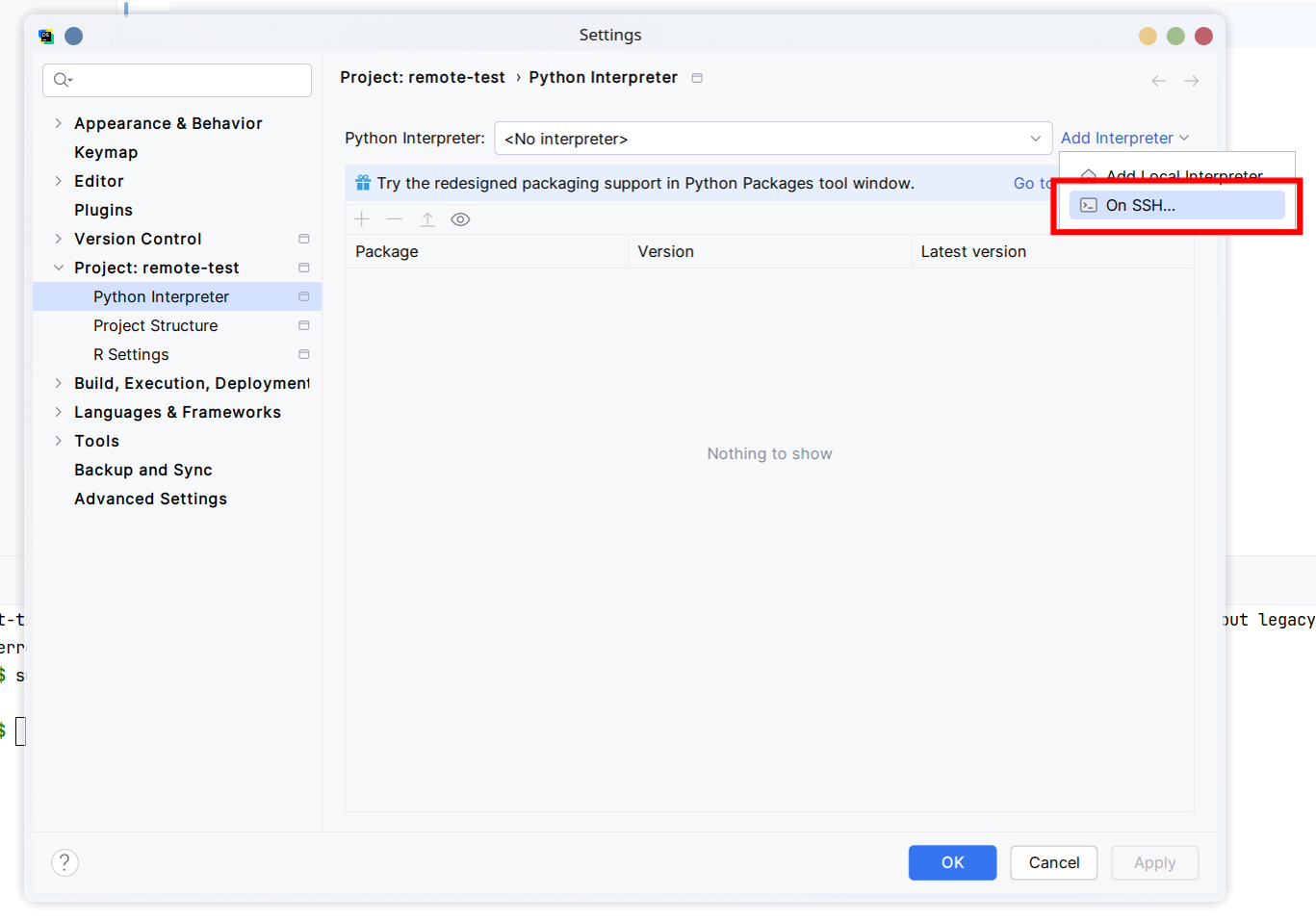
填完信息后,等待连接,就可以指定远程解释器的路径了。我们选择 Conda Environment,并指定远程的 conda 环境。这里我们新建一个名为 test 的环境,使用 Python 3.10。接下来我们需要改一下文件夹映射,将本地项目映射到远程的 /root/autodl-tmp/ 下面的一个文件夹,作为项目文件夹。(不推荐映射到 /tmp 下)
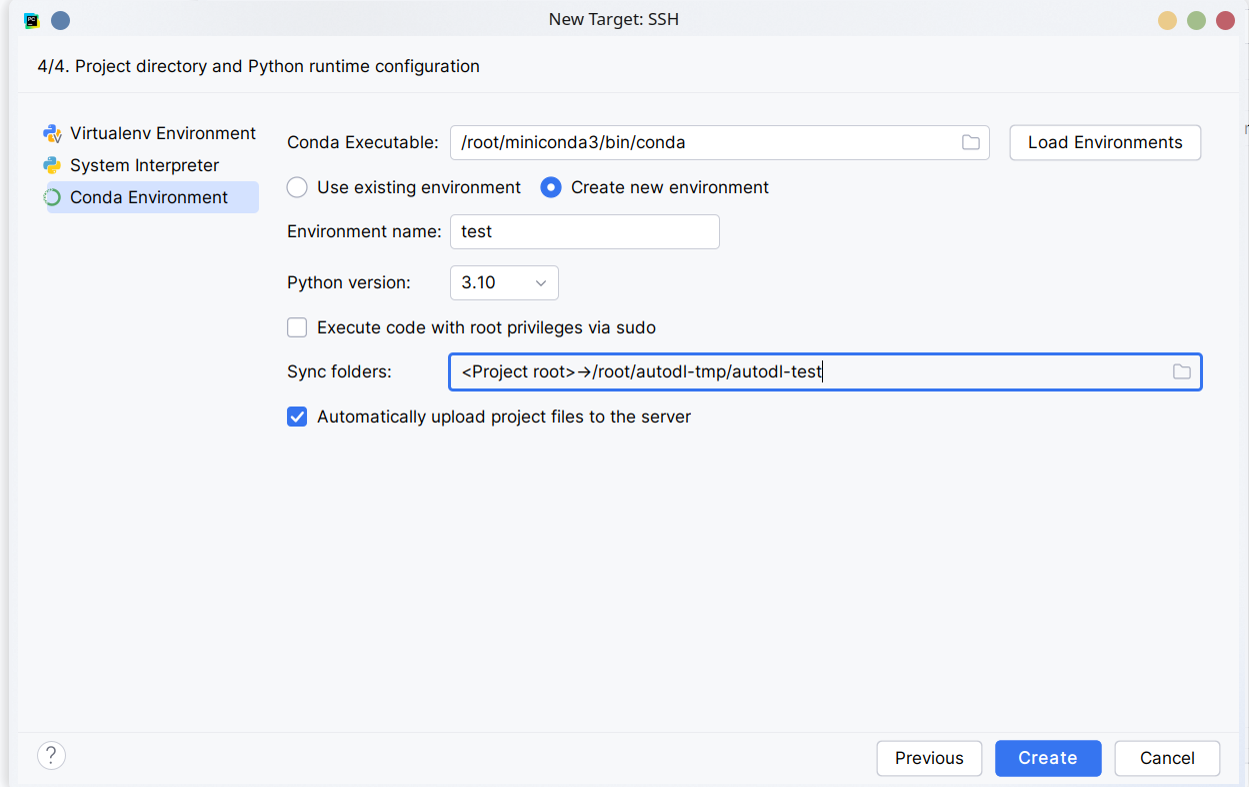
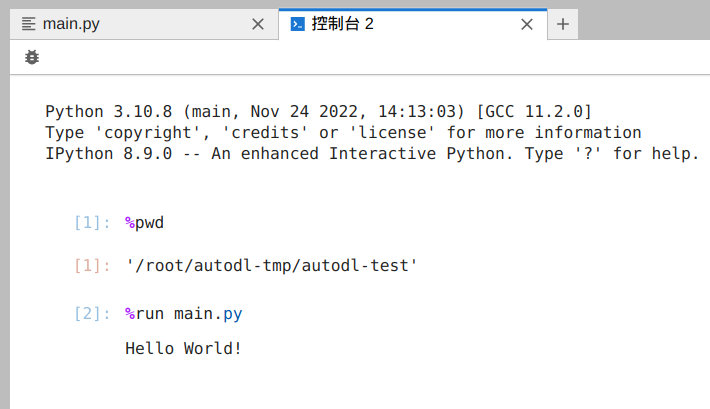
点击 Create,等待新建好环境后,我们就配置好解释器了。配置完成后,我们随便编写一个 Python 脚本。IDE 会自动将我们编写的程序同步到远程服务器上,现在我们就可以运行脚本,并拿到输出了。
开放后端端口
我们也可以给我们的 AI 应用开放端口,具体可以参照 官方文档。下面我们在容器中运行一个简单的 FastAPI 后端,并尝试从本地访问。
AutoDL 提供了一个专门的端口:6006,用于开放自定义服务,所以我们的后端必须开放在 6006 端口上。这里我们创建一个虚拟环境,然后安装 FastAPI:
pip install "fastapi[standard]"接着我们编写一个 Python 脚本,保存为 app.py:
from fastapi import FastAPI
import uvicorn
app = FastAPI()
print('Application Initializing...')
@app.get('/')
async def root():
return 'Hello World!'
if __name__ == '__main__':
uvicorn.run(app, host='0.0.0.0', port=6006) # 注意使用 6006 端口
编写完成后运行 FastAPI 后端:
python app.py开启后端后,我们尝试从本地连接后端。在容器实例界面我们可以看到一个自定义服务的链接,点击后可以看到需要本地运行的命令。这个命令将会把本地的 6006 端口映射至远程容器的 6006 端口。
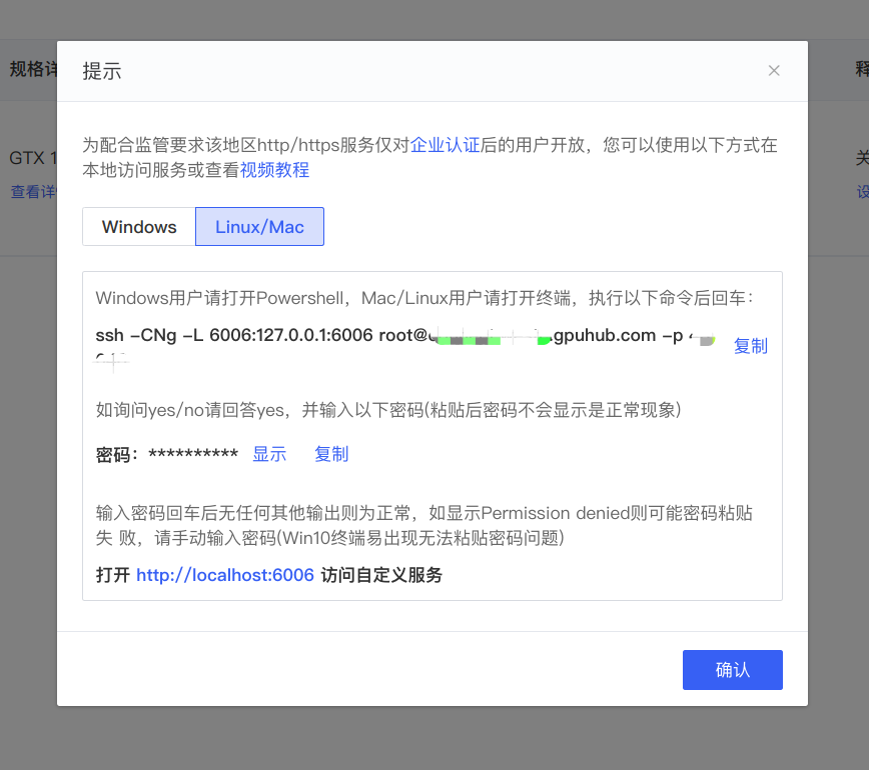
运行命令后,我们在浏览器访问 http://localhost:6006 即可得到:
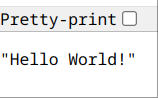
这样我们就成功访问到我们的 FastAPI 后端了。
后记
今天大概过了一下算力云的租赁过程,最开始以为不能开放后端端口,但是后来在查阅资料的过程中逐渐悟了,于是加上了后面开放后端端口的部分。总之从结果上,今天的体验还是比较顺利的,也没有什么搞不懂的地方。那么最后的最后,依然是祝我好运罢!😁